Performant Customizing
This topic contains explanations of performant and non-performant customizing.
Python API
Efficient Use of search_record()/get_children()
Information
The
ppms.search_recordandDtpRecord.get_childrenPython API functions possess adi_listparameter.This parameter serves to restrict the number of data items loaded by the API function.
Unperformant
If an empty list is handed over, all data items from the respective data table are loaded, even if you do not access these attributes.
This leads to an enormously longer run time when loading the respective records.
The more data items are available in the table, the longer it takes to load each attribute.
from ppms import ppms
project_record = ppms.search_record(461, ['000041'], []) # No restriction on the amount of dataitems to load
project_name = project_record.project_name.get_value()
total_remaining_effort = 0
for task_record in project_record.get_children(463): # No restriction on the amount of dataitems to load
remaining_effort = task_record.effort_rem.get_value()
total_remaining_effort += remaining_effort
ppms.ui_message_box(project_name, 'The remaining effort is {}'.format(total_remaining_effort))Performant
The run time of the macro can be reduced by a restriction to the relevant data items.
from ppms import ppms
project_record = ppms.search_record(461, ['000041'], ['project_name']) # The dataitems to load are restricted to "project_name"
project_name = project_record.project_name.get_value()
total_remaining_effort = 0
for task_record in project_record.get_children(463, ['effort_rem']): # The dataitems to load are restricted to "effort_rem"
remaining_effort = task_record.effort_rem.get_value()
total_remaining_effort += remaining_effort
ppms.ui_message_box(project_name, 'The remaining effort is {}'.format(total_remaining_effort))Value Ranges
Database Access in computeOutput()
Subqueries in value ranges
A classic example for non-performant customizing are database queries within a
computeOutput()value range.The PLANTA Server loads modules as follows (simplified):
The module customizing is analyzed in order to determine which data must be loaded.
The data is fetched from the database restricted to the filter criteria.
The value ranges are calculated.
If there is a
computeOutput()value range on one of the DIs in the module, it must be calculated.The calculation is carried out in the data area of each record of this table.
A
ppms.search_record()drops a database query from the server.Since this must happen for each record, there are now n-queries for the data area which reduce run time.
Note
Many computeOutput value ranges can easily be converted to computeSqlValueRanges, which may have a positive effect on the runtime.
Correct Definition of Dependencies
Brief overview
The
computeOutput(),processInput(), andcheckInput()value range functions require a defined list of dependencies.When executing the value range, the dependencies are packed in the DtpRecord of the data item as well.
In the case of
computeOutput(), calculation is carried out each time one of the dependencies changes.
Dependency "asterisk" (*)
A
computeOutput()value range with "asterisk" dependency attempts to calculate itself as often as possible.As long as a data item with "asterisk" dependency has been loaded, each save, reset, and filter leads to a recalculation, regardless of whether the data item exists in this module.
If no module in which the data item exists is opened anymore, it will not be recalculated.
In the case of complex value ranges, the continuous recalculation can lead to run times which are significantly worse.
Alternative
If a data item is to recalculate itself but there are no dependencies that could be entered, there is a tiny workaround that will help you:
Create a virtual data item in the same table as a Yes/No field.
This data item is entered as a dependency in the actual data item with value range.
If you want the data item to recalculate itself, you simply have to invert the value of the virtual DI (
di.set_value(not di.get_value())).
Customizing
Customize Data Areas
Note
In order to prevent runtime issues, we recommend that you always use data fields from the same data table per data area.
Minimize Database Queries
The latency between database and application server is a particularly important point when regarding the performance.
For each database query, a round trip between the application and database server is required:
The PLANTA Server sends a query to the database.
The database answers with the result.
Hence, for any customizing, you should always minimize the number of database queries.
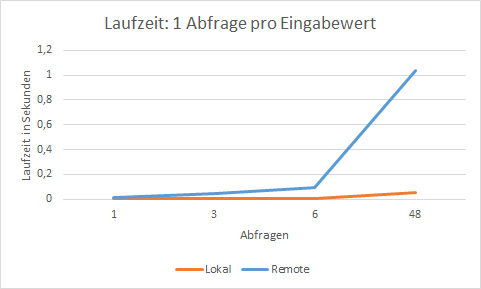
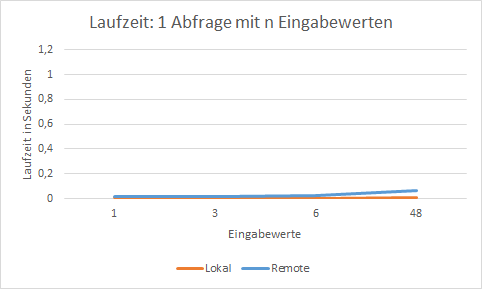
The problem as well as the solution can be illustrated by the following example. For this purpose
two systems have been compared:
"local" system: Database and PLANTA server are installed on the same machine. The latency between the two is less than 1ms.
"remote" system: Database and PLANTA server are installed on different machines. There is a latency of about 6ms between them.
two different Python macros are run in order to fetch data from the database and measure the time.
1 query per input value: It is iterated via a list of resources and a query is sent to the database for each resource.
1 query with n-input values: A list of resources is formated in a query and sent to the database.
The following charts show the increase of run time when a query is made:
Filter Twice
In modules, filtering often takes place twice, which causes an unnecessary increase of run time.
This is often caused by unclean module macros.
If a module is opened initially, the
on_load()andon_initial_focus()functions are run.If both of these methods contain a
Module.menu(12), it is filtered twice.
Delay Module Loading
Loading data in a module always takes up runtime, which is why this should only be done if the user really wants to see the data.
A module is loaded as soon as it is filtered with
Module.menu(12).To delay the loading, filtering must be called as late as possible.
Here, the
on_initial_focus()module method is suitable since it is opened when the user focuses a module for the first time.Whether the module data is yet to be loaded can be checked with the
Module.is_stub()module method.
A submodule which is already opened at module start calls the on_initial_focus() method only when the user clicks in the module!
Here you have to filter in
on_load().
Filter on Virtual Data Items
Filtering on virtual data items is always slower than filtering on real data items
A filter on a real data item is inserted directly in the database query by the PLANTA software in order to restrict the number of results.
For virtual data items you have to fetch all data of the data table from the database and then filter it within PLANTA.
Exception: Data items with value range function
computeSQLValueRangeas well as fetch exits are also queried in a performant manner when loading the real data items
Use of Caches
If a value hardly changes but is often read, you should consider whether it makes sense to float the value.
You should ask yourself the following questions:
How often is the value retrieved?
A value which is only retrieved 1-2 per session is not a good caching candidate.
How long does it take to detect the value?
It is not worth the effort to cache simple calculations that are detected in a fraction of a second since here the effort of setting up and invalidating the cache exceeds the benefit.
How often does the value change?
Values that frequently change are good cache candidates, unless the calculation is longer and the values are often required at different positions anyway.
When do I have to empty the cache?
Often the cache is emptied if the value changes. In some cases it may also be sufficient to reset the cache at some positions in the code, if you know that only the successor code uses the cache.
From where do I have to be able to empty the cache?
If I offer a function with cache in a module, there has to be a function to empty this cache as well.
LRU cache
Tripping Hazards
The parameters of the cached function and the return value should be primitive data types (ciphers, texts, ...), PLANTA data types (DtpRecord, DataItem, ...).
If I-texts are to be cached across sessions, the user language must be a part of the parameters, otherwise the I-text is cached in the language of the user that calls the function first.
Example code
import functools
from ppms import ppms
@functools.lru_cache(maxsize=None)
def get_dataitem_attributes(di_id):
"""Return the attributes of a DI or None if the DI is not valid"""
di_record = ppms.search_record(412, [di_id], ['column_type', 'df_length', 'dt', 'di_name', 'format_id'])
if di_record is None:
return None
column_type = di_record.column_type.get_value()
df_length = di_record.df_length.get_value()
dt = di_record.dt.get_value()
di_name = di_record.di_name.get_value()
format_id = di_record.format_id.get_value()
return column_type, df_length, dt, di_name, format_id
def cache_clear():
"""Clear all caches used in this module"""
get_dataitem_attributes.cache_clear()Database
Use of Indexes
Information
If queries are often filtered via the same search criteria, a performance improvement can be achieved by setting indexes on these search criteria.
The respective type of index depends on the database.
- Performance Counting
- Performance-Aufzeichnung
- Performance-Aufzeichnung
- Performance Counting
- Performance Counting
- Performance Counting
- Performance-Aufzeichnung
- Performance-Aufzeichnung
- Performance-Aufzeichnung
- Performance Counting
- Performance Counting
- Performance-Aufzeichnung
- Performance Counting
- Performance-Aufzeichnung
- Performance Counting
- Performance-Aufzeichnung
- Performance Counting
- Performance-Aufzeichnung